
Is it possible to develop and deploy machine learning systems without urgent debugging, downtime and catching your hair on fire?
Yes, but you’ll need to start with the right goal in mind.

Figure 1. No one likes to drop a brand-new ice cream and we have all learned how not to drop it. An undeployed or unstable deployed machine learning system is of as much use as a dropped ice cream, so let us make sure to deploy robust ML systems.
If you’ve ever put a self-developed machine learning (ML) model into operation, you’ll know that errors in the operational setting can render the ML system fragile or even unusable. The result will most likely be hectic debugging and downtime.
Worse, many projects involving artificial intelligence (AI) methods such as deep learning or more traditional ML do not even make it to the deployment stage. As Eric Sigel, Ph.D. and former Columbia University professor notes in the post Models Are Rarely Deployed: An Industry-wide Failure in Machine Learning Leadership – Kdnuggets, surprisingly few ML projects make it into operational settings where their predictions and analyses are meant to produce value. Instead, the outcomes of investments in AI and ML projects end up lying around unused in virtual piles, like piles of unorganized and thus undiscoverable value in books.

Figure 2. While books can be useful, they are not if they are stored in messy piles and not used. This is the same for undeployed ML and AI models that lie around in outdated binary model files.
It’s easy to be smart in hindsight and plan how to avoid specific problems in the future. However, this approach will only solve the problems that happened to materialize in a specific setting without treating the underlying cause. I advocate that having the general operational setting in mind from the initial development phase will minimize the risk of operational issues appearing unexpectedly by targeting the underlying problem of unpreparedness for the operational setting. Like Andrew Ng says (Scale Transform 2021 - From Big Data to Good Data with Andrew Ng - YouTube, 6:50), “when you deploy in production, you’re only maybe halfway there”, so it should not be seen as the final step of an AI or ML project. Instead, getting a first version of an ML/AI system into production is a very important first step. This will allow you to start testing the data flow and handle challenges related to deployment in parallel with the ML/AI model development.
In this post, I will describe some of the challenges I have seen when deploying ML systems and how to avoid them.
The setting
The issues in deploying ML models often stem from the way that many data science projects are run, starting with a research phase decoupled from the operational setting. In this phase, analyses are performed to determine the best prediction approach, which then needs to be operationalized.
At this point, one might realize that the focus on achieving high predictive performance without considering the operational settings, has provided fertile ground to sprout deployment issues.
The Example
I’d like to introduce an example ML system that performs time series prediction to demonstrate some of the issues more concretely. In this example, we have image data as input from one data provider and sensor data as input from three other data providers. Each of these input data sources are in near real-time, with new data arriving from each data provider approximately every 10 minutes. There are some delays in the data flow pipeline, so the most recent observation time in the newly arrived data is between 20-40 minutes prior to the current time. The system is depicted in Figure 1.
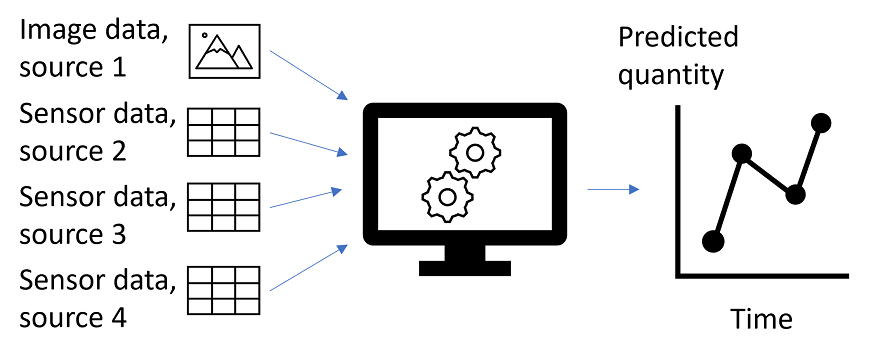
Figure 3 Example of operational ML system with a variety of input data sources. The ML system outputs a time series prediction.
The issues
A variety of issues can occur when moving into the deployment phase of a project. While the issues may seem independent from each other, they are all manifestations of the underlying problem that real-world constraints were not considered during the research phase. In the following I will describe typical issues, and how they can be solved.
Static ML model file
One way to deploy a model is to upload a binary file containing the trained ML model from the research phase to a deployment platform. Such a binary file may require specific versions of dependencies in the code, preventing updates of other dependencies. Additionally, retraining the model is cumbersome since it requires downloading new data to a local laptop and rerunning all training steps.
On the Azure cloud platform, Azure DevOps pipelines can be combined with the Azure ML Studio to allow easy retraining of the ML model and updating of dependencies in the environment.
Data source failures
In a production setting, IT infrastructure may break down. Breakdowns make real-time data unavailable for the ML system, stopping the ML system from providing predictions. In the example, this could happen if the data provider for image data has internal IT issues, as shown in Figure 4. When this happens, data can often still be collected for future purposes. Hence historical data used during the research phase would not necessarily reflect breakdowns and such data disruption will only become apparent in the operational setting.
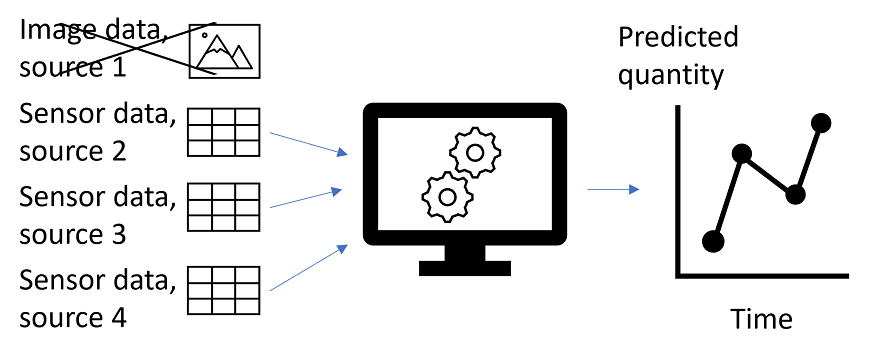
Figure 4. The example ML system without data source 1.
One solution is to build different ML models, each dependent on different data sources. This can make the system more robust, but also incurs additional costs in terms of ML model maintenance and development, and for financing several deployed models.
Data delays
When building machine learning models in order to make predictions with a 20-minute horizon in the research phase, the model would be trained to predict the target data observed 20 minutes later than the most recent input data. In the operational system, data sources may have delays between being observed to being available as input to the ML model. This means that a model trained to predict 20 minutes ahead given input data at time t would make predictions for time t-10 if the most recent available input data was observed at time t-30. “Predictions” for the past are obviously undesirable, so this needs to be avoided and handled during development of ML models.
The solution to this issue is to train models with input data with the correct time stamp relative to the target considering when the input data is available in the operational system.
Cloud costs
Initially, cloud costs may be low, partly due to some services being free to a certain usage threshold. As reliance on cloud services increases, costs can explode. Price structure complexity and a setup using different services can complicate cost reduction.
Additionally, certain aspects of a cloud setup risk being more expensive than necessary due to limited knowledge of pricing at project start. It would, for example, be easy to reduce data traffic costs by setting up cloud services within the same geographies and virtual networks initially, while changing these later is more involved.
To minimize unpleasant cost surprises, a basic understanding of costs should be in place before deciding to use a cloud platform for an operational ML system. Additionally, it is important to set up budgets and/or cost alerts on cloud subscriptions to get notified if costs exceed the expected price.
Numerous cloud services
With each new cloud service in a system, the risk of a service failing will increase. In the example ML system, there might be cloud services for:
- handling ingestion of the sensor data into a database,
- ingesting image data
- preprocessing image data
- copy data from different landing places to a common data storage location
- hosting the deployed ML model.
Since the ML system only works if all services run, each additional service decreases the ML system robustness. For more on this, Microsoft offers an Azure Learning Path in which this is covered at Design your application to meet your SLA - Learn | Microsoft Docs.
To avoid such issues, ask someone with experience in cloud services for advice.
The solution
The underlying cause of the above issues is the failure to think in terms of operational constraints from the outset. While there are solutions for the concrete problems, it would be better to avoid such issues entirely. A general barrier against operational issues is to plan with deployment in mind from the beginning and deploy as soon as possible.
Summary
Many operational issues arise from implicit assumptions made in the research phase, which were never tested in the operational setting. Such issues could be avoided by starting the project in the operational setting, deploying a simple operational data flow and prediction model as a first step.
This approach unearths issues one at a time, giving room to solve system failures in a structured way and take data issues into account during ML/AI model development. Sometimes it is not possible to start development in the operational setting and the second-best strategy is to keep an operational mindset, always thinking about implicit assumptions and consequences of operational constraints on modelling options.
