
Introduction
The best projects are when you can use state-of-the-art AI to solve challenging problems and help make the world a better place by doing so! We’re going to describe one such project today and are hoping to take you briefly through our process of problem-solving in so doing.
By Bethan Cropp and Daniil Shantsev
Costa Rican Red Cross responding to flooding using DREF funds (Credits: Costa Rican Red Cross)
The International Federation of the Red Cross/Crescent (IFRC) deals with lots of diverse data, often free-form, unstructured written data. The case we worked with concerned reports about disaster responses for the Disaster Relief Emergency Fund. After a disaster the IFRC wants to examine their response, challenges faced, what went well, and lessons learnt. This is crucial in improving their disaster response, targeting money and aid more effectively, and generally improving outcomes in the wake of a flood, epidemic, earthquake, or the like. The learnings and challenges are summarized in reports as short statements called excerpts. It’s great to tag these excerpts with certain categories to better arrange and understand them so as to draw better summaries and conclusions on certain aspects of disaster response. In 2021 this was done manually, first by an initial tagger – who must have extensive training, then corrected by an expert human tagger. Unfortunately, the Red Cross was experiencing a backlog of untagged excerpts. Our job was to see if we could use Natural Language Processing (NLP) AI to tag these reports automatically and remove this backlog. The Red Cross team shared their impressions of this project in “Opening the black box — building systems which help us learn together”. In the current blog post we share our impressions and give more technical details.
To start with we had a set of 312 documents, with around 5000 excerpts, a small dataset. All excerpts were tagged in a system with 41 possible tags, and each excerpt could have several tags – a multilabel classification problem. Additionally, these excerpts came from PDFs, so we needed a way to manually extract the relevant excerpts. This is also a challenging task since PDF format is optimized for portability rather than for text extraction: various text fragments such as tables, figure captions, titles, and footnotes, as well as page breaks create additional problems. So, the first accuracy metric for our tool was the percentage of excerpts correctly extracted from a PDF, with a result over 90% i.e., we saved over 90% of human labour on that subtask.
The next task is to tag the excerpts. As an initial assessment, we noted the accuracy of always assigning to the most popular category (as this was better than randomly assigning). This is a great way to start as it lets you know whether your model is picking up anything from the data. We then built a simple “baseline model”. This is something quick and basic that gives you confidence in a fancier model doing well. Also, if you get good performance out of a simple model, you might not need to develop the more complex model. In our case we worked with a Naive Bayes model. Essentially this looks at the probability of each word being somewhere in an excerpt with a given tag. The good news was the Naive Bayes model outperformed our baseline! Hence, the data did have some predictive value. 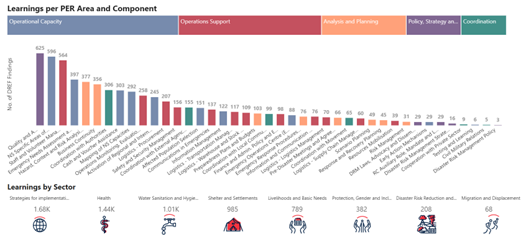
The Operational Learnings – Our tag labels (Credit: IFRC Go Platform)
Building a state-of-the-art model
Now we want to go from a model that sort-of works, to a model that is “good enough” or ideally “human-level”. As we don’t have a huge amount of data, the way forward here seemed to involve transfer learning.
Transfer learning has been used effectively in several AI fields, notably in image recognition. In the case of, say “cat image recognition” you might start with a deep neural net trained on ImageNet. After that you can strip out the final classification layer from the pre-trained model, add a binary layer, and carry out fine-tuning, e.g., training on a small sample of “happy cat” and “grumpy cat” pictures. All understanding of things like edge and pattern detection that are present in the pre-trained model are thus retained, so you get good accuracy from a smaller training set.
For the current NLP task, we decided to use a BERT model. BERT stands for “Bidirectional Encoder Representations from Transformers” and has become a popular system for all sorts of NLP tasks, from translation and text auto-completion, to what we need – text classification. We settled on using a DocBERT system, using a transfer learning process developed by the University of Waterloo (code here ). This BERT model has been pre-trained on a large corpus of data from the internet, so it has a broad understanding of language, the relation between words, and how meanings vary with positioning and context. We then added a fully-connected layer over BERT’s final hidden state and retrained the entire model on the small IFRC dataset to make sure the model learns the specific classification task. We also tried alternative BERT-based systems and some competing types of neural networks, such as LSTMs, but DocBERT delivered the best results.
This seemed to get us properly into the “good enough” territory, so we started running some test cases with the expert tagger. We were happy to see that in many cases the expert considered tags assigned by the model to be a better choice than tags assigned by a non-expert human. Now we have two issues to deal with: how to improve the model further, and how to get our model into use.
Model Training and Improvements
- For training purposes, the dataset was split into TRAIN, DEV and TEST portions, the latter two being 10% of the data each. The training was performed on the TRAIN data only and stopped when F1 measure on the DEV data did not show improvement over 5 epochs in a row.
- The excerpts contained 33 words on average, while the longest one was 305 words. We set the maximal length of 64 words to split longer excerpts to speed up training without accuracy loss.
- There is a number of Red Cross specific abbreviations in the DREF reports that the pretrained BERT model probably doesn’t recognize and a small quality improvement was achieved by replacing them with the corresponding full texts.
- We tried to include meta data such as hazard type (flood, earthquake etc.) in the excerpts, however without a clear accuracy improvement.
- IFRC wants every excerpt to have at least one tag, while DocBERT model won’t assign any tag to an input if all tags get too low ‘score’. We modified DocBERT to force assigning a tag that has maximal score. It changed the training trajectory a lot, but had ambiguous effect on the tagging accuracy.
Usually, after 15-20 epochs F1 metric on the TEST dataset reached saturation on the level 50-55%. A human expert gave an even higher quality assessment indicating that only 26% of excerpts got unambiguously wrong tags. 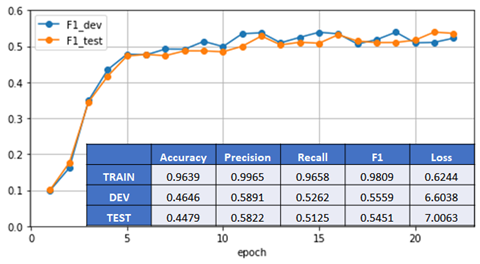
Convergence during model training on the Red Cross data
Deployment and Conclusions
The Red Cross has its own platform, the GO platform where they collect information on distasters. We wanted them to be able to, at their leisure, incorporate our model into this GO platform. We therefore need something be stable, modular, decently documented, and using technology IFRC are mostly familiar with. We decided therefore to work with FastAPI written in Python, which we deploy inside a docker container. These are nice light-weight tools that we regularly use for deployment of models. A development version of the API was shared as an Azure app so that the feedback from the expert tagger could be collected. 
The Go platform (Credits: IFRC Go Platform)
We also had the pleasure of working side-by-side with the IT team of IFRC, including the data scientist who would maintain, and possibly further work on, our code. Having the opportunity to go through our code together made for a super successful handover as IFRC was confident that if some detail of their tagging system changes, they can adjust their model to suit their needs with no further input from us. Google Colab turned out to be a nice collaboration platform for sharing code that can be edited and run by both parties: a code example that carries out model training on the IFRC data can be found in a shared Colab notebook. Using Colab’s GPU training takes around an hour (over 10 hours with CPUs).
At the end of the project, we had a high functioning model working at about human-level, callable by an API that can be integrated into the GO front end, the backlog of untagged reports was cleared, the need to have and train initial taggers was removed, and the internal team had a good understanding of how the model functions and how to retrain it. You can find code related to this project at the IFRC Go public repository. 
Fiji Red Cross and IFRC teams in Fiji assemble to assess damage caused by Cyclone Yasa in December 2020 (Credit: IFRC/Ponipate)
This was a fun project in a lot of ways! It’s great to see an important non-profit take data-driven decisions and develop data science solutions in a sustainable way. We got to work with advanced NLP systems and helped in a small way to aid the Red Cross improve their response to disasters.
Get in touch with us if you want to discuss similar cases!
